
初めに
立体視のある3D画像やモデルは現在、幅広い分野で使われています。人工知能(AI)はすでに従来それを作り上げるための時間と手間を大幅に削減しました。
3dモデル 作り方が多様化になり続ける中、普通の2Dの画像を製作材料にするだけで画像や写真3D化をすることができます。
今回は2Dの画像を3Dの画像やモデルに変換できる技術と事例を紹介していきたいと思います。
3D画像の応用のシーン
3D画像やモデルの応用分野を考えますと、下記などの事例は挙げられます。
- ゲームのキャラや背景
- インテリア設計プラン
- 建物の効果図
- VR(仮想現実)
- AR(拡張現実)
- 動画CG
- 芸術創作
- 教学デモ
- ニコニコ動画のMMD動画
- YouTube投稿の自作3D動画
画像を2Dから3Dまで転換するAI の技術の発展
AI=artificial intelligenceは人間の知能の運び方を真似して具体的な問題に対して判断力と処理能力を絶えずに強める技術です。人間学習のように一定の資料と素材をインプットして機械学習の段階を経たら自動に任務完成や問題解決などの結果を導きます。
もちろん、人間の大脳の神経網のような物理的基盤であるニュートラルネットワーク(Neural Network)と運行のロジックを定めたアルゴリズムが必要です。
画像を2Dから3D図やモードに転換する3dモデル 作り方は、転換の方式から考えますと、三つのタイプがあります。
- 対象物体の大量の原始画像をインプットしてそれらを依拠にして物体の3D画像を構築するタイプです。
- 一枚だけの画像をインプットし、そして人が方向などのパラメータを指定して3Dの様態を生成するタイプです。
- 一枚だけの画像と、前もっての大量学習によって形成した転換の取り扱い方法で、全自動かつ急速的に3D画像・モデルを生成するタイプです。
次はそれぞれのタイプに対応する事例を挙げてみます。
1、Autodesk Project Photofly

3Dモデルを構築するためにこの製品は40枚ぐらいの画像を使うのが必要です。なぜなら、当サービスによってこれで実物の的確なサイズ比例と寸法を測定できるのです。このdモデル 作り方では99パーセントぐらい正確さを確保できると言います。
当ソフトには物体表面の肌理のライブラリーが設けられていますので、出来上がりの3D画像の効果をよりリアルに見えるようにすることができます。この製品を使って3Dスケッチを作ることや、本物とそっくりの3Dモデルの製作をすることができます。
原始の画像の枚数が40になっていない場合、画像の数を少な目にしても製作可能ですが、完成品のリアル感も当然下がります。 商品や版権のあるものに写真を取りにくいなら、まず身近な物体から原始を画像を撮影してこのソフトで2D画像 立体化をしてみてください。
2、3-Sweep
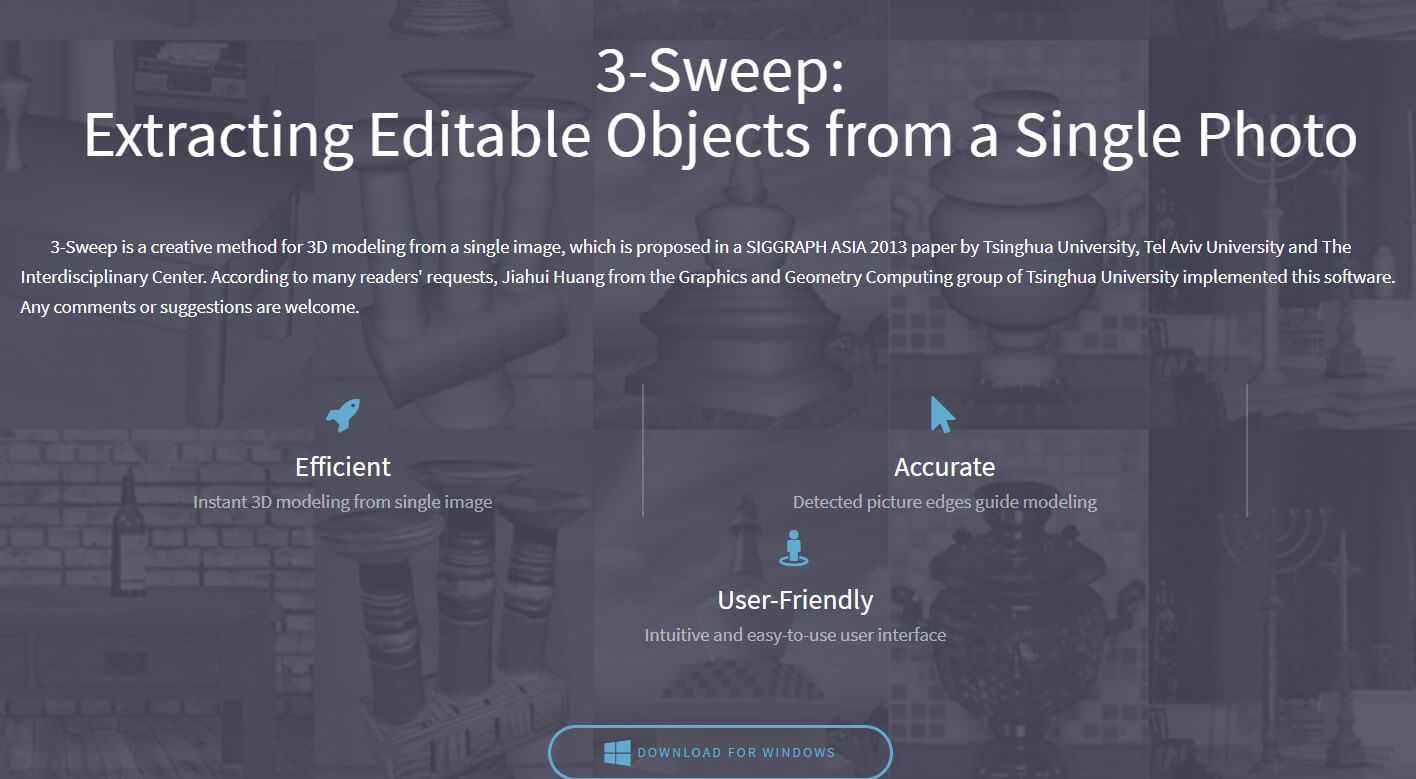
3-Sweepは3Dモデルを作るために開発された一つの独特のソリューションで、一枚だけの画像から立体視の強い3Dモデルを作れます。清華大学とアビブ大学の共同研究によって得られた成果です。
このプログラムでユーザーにとって必要な手順は、原始画像の方向を規定することと、マウスを目標物体のボディラインに沿って移動することです。他の仕事、例えば、3D画像の生成、2D画像から肌理を抽出してモデルにつけることなどは全部このプログラムに任せていいです。
2d画像 立体化するために、枚数の多い画像、複雑なインターフェース、アーティストとしての素養などは全部いらないです。
3、NVIDIAのDIB-R
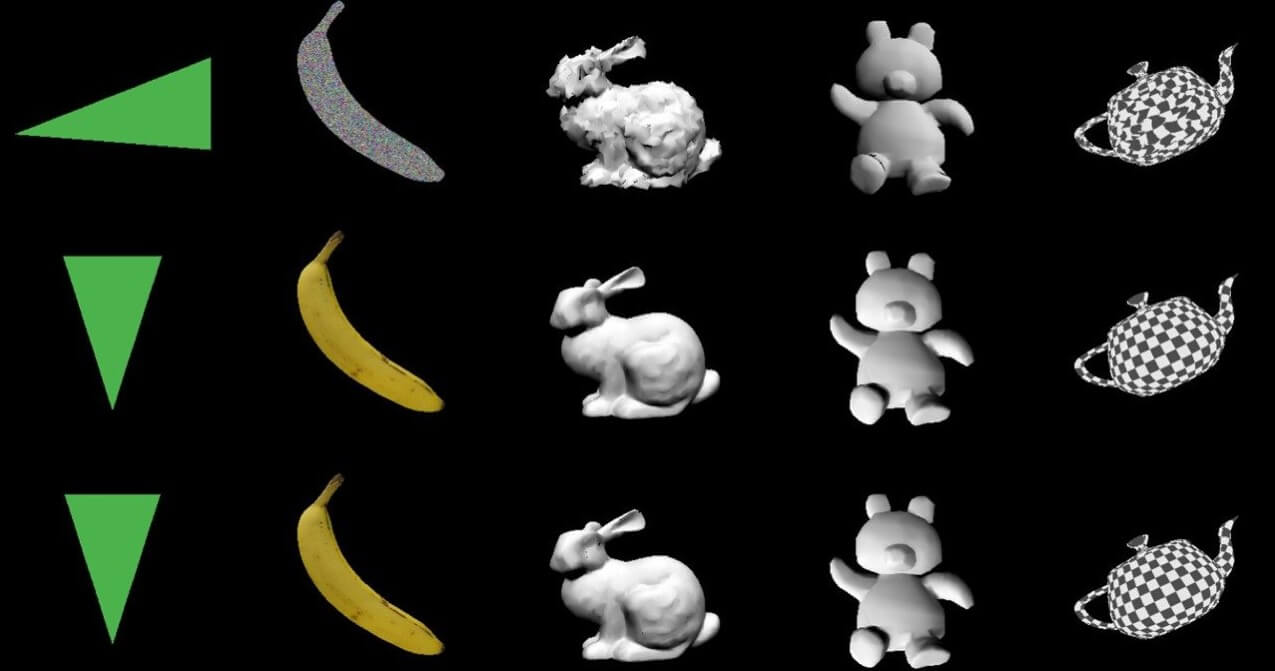
DIB-Rは「differentiable interpolation-based renderer」の略語で、翻訳すると「微分可能関数内挿をベースにしたレンダラー」となります。 左目を閉じてスクリーンを見て、次に、右目を閉じて左目を開きます。
どちらの目を使用しているかによって、視野が変化することがわかります。 それは、私たちが2次元の画面を見る時、網膜によってキャプチャされた画像が組み合わされて、3d画像の感覚を生み出すからです。
機械学習モデルは、画像データを正確に理解できるように、これと同じ機能を必要とします。NVIDIAの研究者たちは、2D画像から3Dオブジェクトを生成するDIB-Rと呼ばれるレンダリングフレームワークを作成することで、これを可能にしました。
従来のコンピューターグラフィックスでは、3Dモデルを2D画面にレンダリングします。 ただし、逆のことを行うと価値のある情報を得られました。たとえば、2d画像 立体化をするモデルは、より優れたオブジェクト追跡の機能を実行できます。
NVIDIAの研究者たちは、このモードを機械学習技術と統合しながら、3D転換を実現できるアーキテクチャを構築したいと考えていました。 その結果、DIB-Rは、形状、色、肌理、照明などのレベルで高忠実度の写真 3d化を実現しました。
単独のNVIDIA V100 GPUでこのモデルを大量的にトレーニングするには2日かかりますが、NVIDIA GPUなしでトレーニングするには数週間かかります。 訓練が終わった時点で、DIB-Rは2D画像から3D物体を100ミリ秒未満で生成できます。 この技術のソースコードをNVIDIAがGithubで開示しました。
他の技術、製品、サービスの事例
以上の三つの技術の代表例を見て二次元がどういうふうに三次元に変わるのかちょっとだけ見当を感じるでしょう。続いて、ほかの技術、製品、サービスの事例を紹介したいです。
1、SurfNet
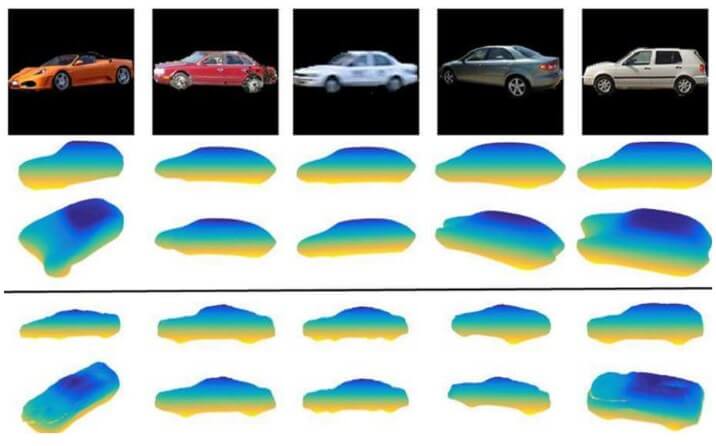
アメリカインディアナ州のパデュー大学の団体はAIを通じて2Dの画像を3D画像・モデルに転換する技術を開発しました。同チームが公表した成果は車の画像を3Dのモデルまで積み上げる事例です。
研究の責任者によりますと、カメラに撮られた画面をリアルタイムで3Dモデルに転換できるという目標を掲げているといいます。 この技術は自動車の自動運転に応用される潜在力が大きいです。未来この技術は瞬時に画面を処理できるとともに、数の少ない2D画像を立体化して3D画像を作り上げられるという二つの特性を同時に備えないといけないです。
その特性に近づけるために、2Dの自動車画像と3Dの自動車モデル図を十数万ほどAIが学習をさせられています。機械学習の量が増えるにつれて、SurfNetの構築精度もあがります。
今後のアルゴリズムの改良によって、SurfNetの性能がさらに向上する見通しです。 残念ながら、同開発チームはアプリやソースコードなどの内容を大衆にリリースしなかったです。
2、Volume
このサービスの公式ページによりますと、Volumeは単一の2Dイメージの要素を分散させて3Dの空間で再構築するツールです。この処理のロジックで写真 3d化をすることも実現できます。
単独の情景の2d 画像を3Dアセットに変えられるこのツールが誰でも簡単に使えるように開発されています。ユーザーが出力した3D画像をARとVRの分野に応用することをVolumeは励ましているので、無料のAPIを公開しといています。
Githubにもソースコードが公開されております。 このツールで実際に完成したものの例をご覧ください。完成した3d画像の正面からと側面からの様子です。


点状のノイズ部分は3D空間でピクセルの奥行きを決めたプロセスの痕跡です。これにより、元々の廊下の図面は確かに立体視を表せますが、画質の劣化も深刻です!当サービスのこれから整備すべき所がまだ多いでしょう。
3、デモアプリ
バイタリフィアジア会社の人工知能研究チームはが開発したこのデモアプリは、コンピューターからもスマホンからも、誰もが簡単に二次元の画像から三次元のモデルに作れることを目標としています。
デモアプリはウェブサイトという形を使ってユーザーの使用の利便性を高めました。それでは、公式サイトから使い方を見ていきましょう。
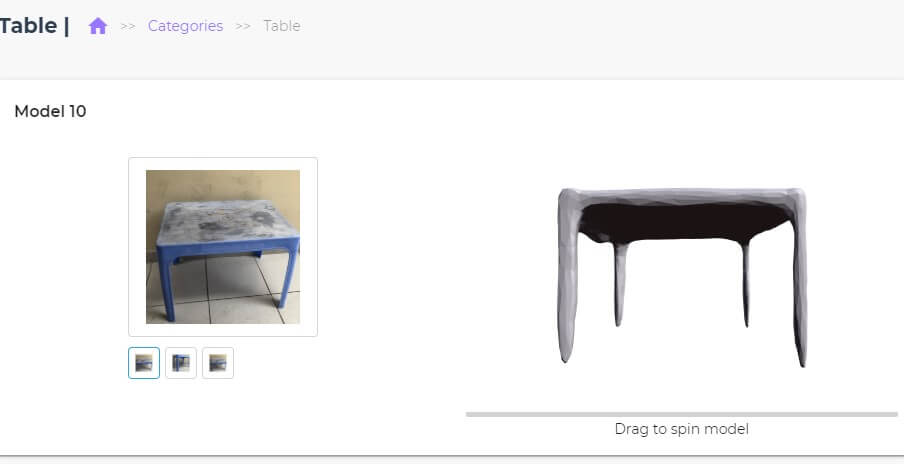
ホームページのダッシュボードから予め規定された物体の類別を選んでください。クリックして中に入るとサイトが指定した実物の写真とそれに基づいて生成された3D画像モデルが展示されています。
3Dモデルの画像はマウスで視角を自由に切り替えられます。ホームページで示されている実物の類別が結構多いですが、3Dモデルが結構雑な感じですなぁ。しかも、自分で実物の画像をアップロードして3Dモデルを作ることができないです。
ホームページのメニューからSamplesを選ぶと物体を指定して「Generate」ボタンを押せば3Dモデルが出てきます。しかし、またユーザーから提供される実物の写真は使えなくて、全部サイトが限定した写真です。それに、おかしい図がたくさんあります。一つの例を挙げます。

なんだこれ?本当の机の写真かどうかはさておき、この地下鉄の宙に浮かんでいる様子はなんなんだ?ようするに、このオンラインAI3Dモデルメーカーはまだ不完全です。これから改善しないといけないでしょう。
4、SMPLify
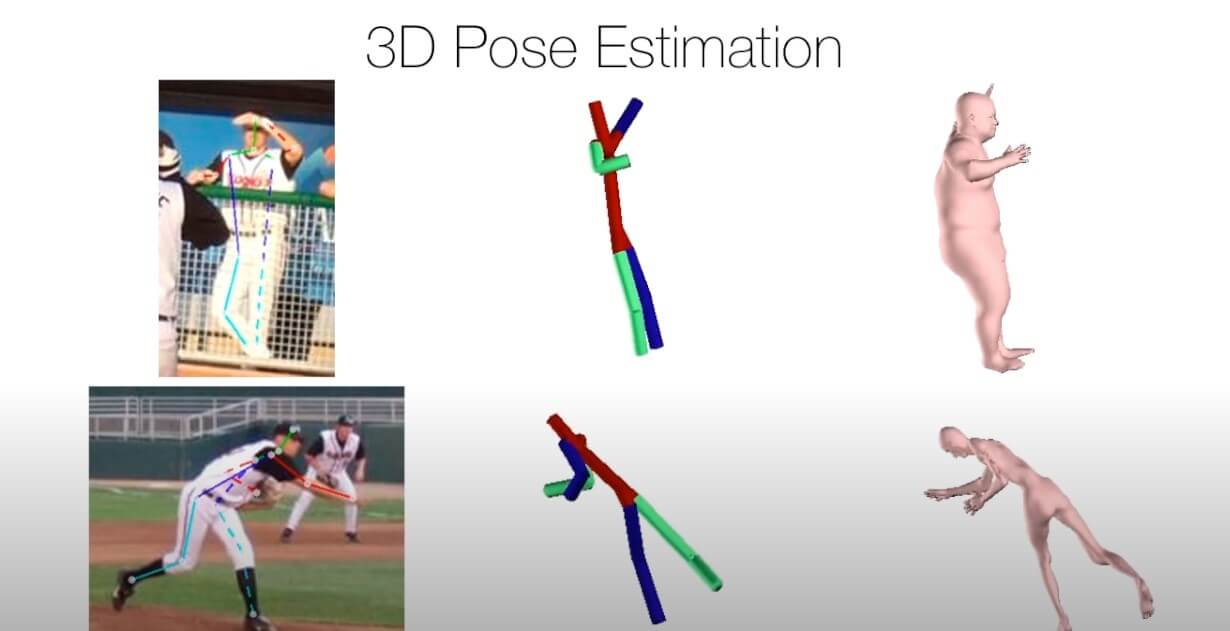
この技術はたった一枚の人間の写真から、その写真のポーズを含めた人物画像を3Dモデルまで構築するという写真 3d化ができます。ではその手順やロジックをざっくりと説明していきます。
この技術はボトムアップというロジックで人体の3D画像・モデルを作ります。つまり骨の位置から人間の体形まで充実させるという過程です。 まずは、最先端のたたCNNs=Convolutional Neural Networks(いわゆる「たたみ込みニューラルネットワーク」)を使って人体の関節の位置を探知して記録します。
そして、関節を連接することで人体の「骨」の位置を描きます。次に、「骨」に「肉体」を添加することで、人体を充実させます。 そして、その肉体を元の写真にある人体とどれほど体形が合ったか、3d画像を写真の人体と同じ比例に設定して重ねることで比較します。
モデル人体の各部分のサイズが写真と同じぐらいになるまで「肉体」のパラメータを調節します。最後に、写真 3d化した3d人体の不自然な角度を、人工知能が人体構造に対する大量的学習の結果と対照し、是正します。 コードが提供されています。
5、AutoHair
この技術を使って髪の毛の3D様式を自動的に生成することができます。しかも、一つの大きいメリットを持っています。それは、髪の真実さを最大限度で再現することができます。
なぜなら、この技術は厳格的に言いますと、モデルを作る原理で働くわけではなくて、シミュレーションという原理を使っています。前者が物体の幾何の属性を再現するのに対してシミュレーションは物体の物理の性質、例えば、受ける力、密度などをシミュレートします。
従って、もっと自然に見えます。 ニューラルネットワークを使うこの技術はモデルの髪の毛が頭と如何に自然に結合できるかという問題を上手く解決しました。ユーザーは自分で髪の毛を自然に頭に合わせるように調整をする必要はないです。

今回の3D構築の事例と応用のシーンを下表のとおりにまとめています。
| 3D画像生成の事例 | 応用のシーン |
| Autodesk Project Photofly | 任意の物体 |
| 3-Sweep | 方向性が明らかな物体 |
| NVIDIAのDIB-R | 任意の物体(急速合成) |
| SurfNet | 車の3Dモデル |
| Volume | 写真に深さをつける |
| デモアプリ | 机など家具の3D画像 |
| SMPLify | 人体3Dモデル |
| AutoHair | 髪の毛 |
まとめ
今の段階の技術を見ると、2Dの画像を使って3Dの画像に変換すれば、プロセスはまだ複雑です。多くの最新技術は一般のユーザーでも使えるアプリにまで発展していないです。変換と合成の最終の効果から見ると、硬くて自然ではない所もあります。
しかし、運用のシーンはたくさんあって未来性の大きい技術としてこれからどんどん発展していくでしょう。


